方法
JVM内存结构
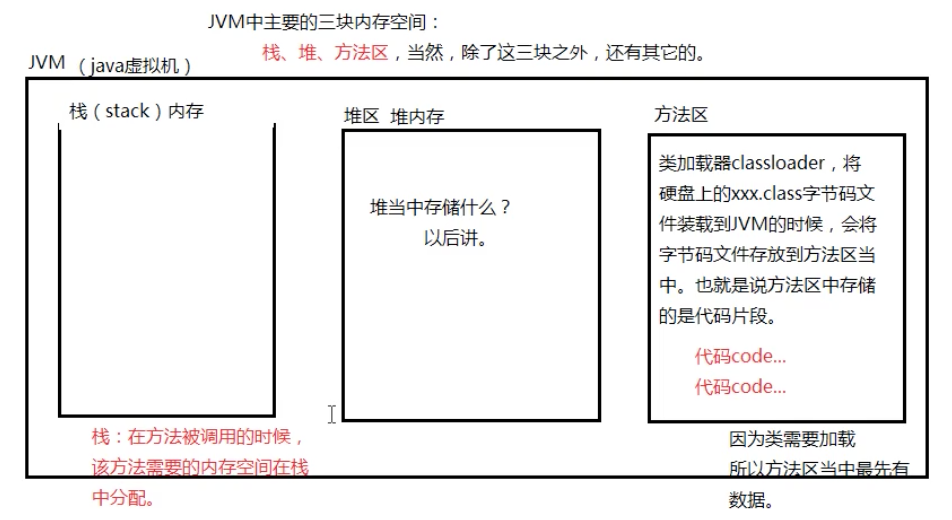
方法区最先有数据,方法区中存放代码片段,存放class字节码。
堆内存:后面讲。
栈内存:方法调用的时候,该方法需要的内存空间在栈中分配。
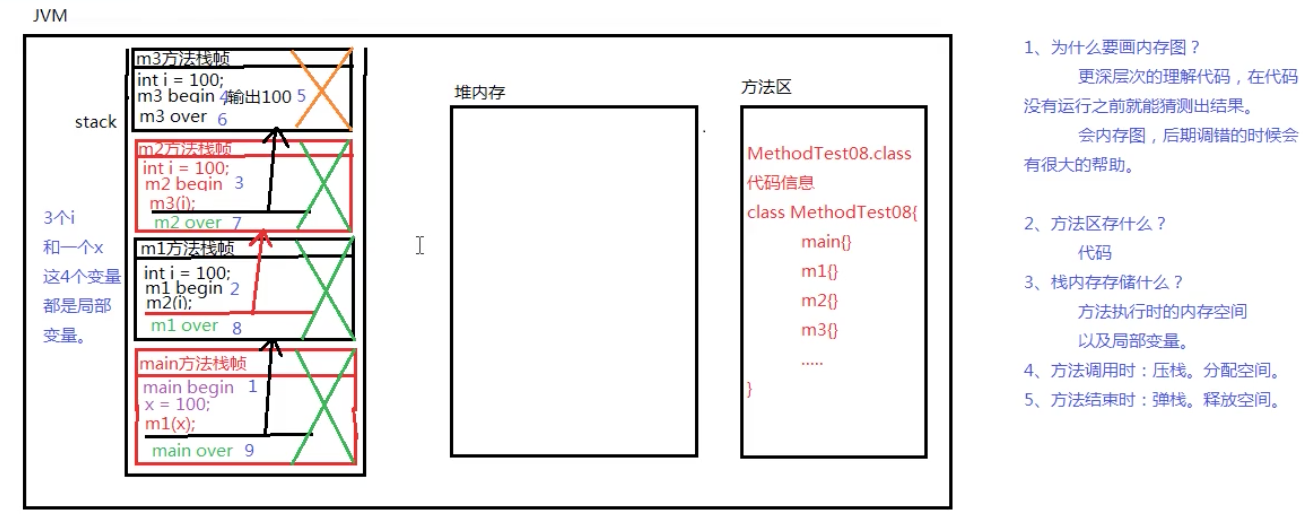
方法只有在调用的时候才会在栈中分配空间,并且调用时是压栈。方法执行结束之后,该方法所需要的空间就会释放,此时发生弹栈动作。
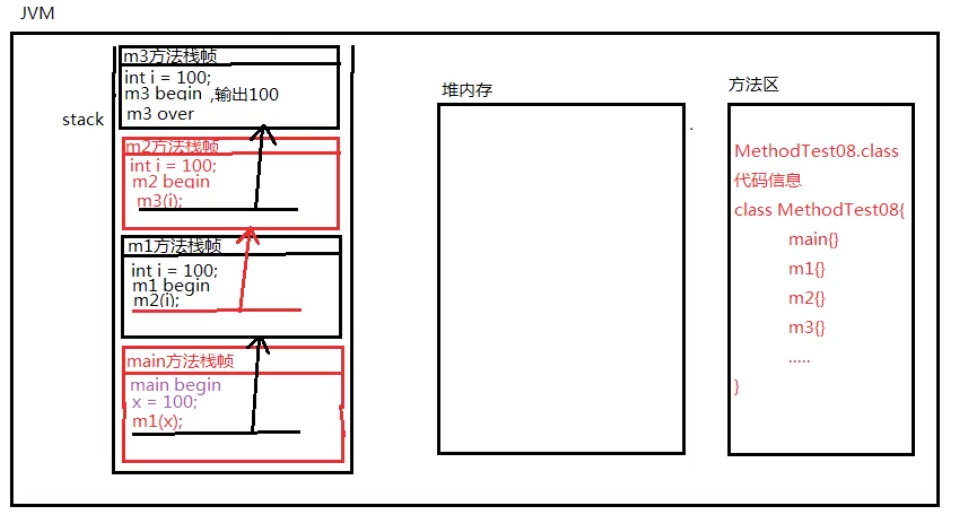
方法执行时内存变化
public static void main(String[] args){
System.out.println("main begin");
int x=100;
m1(x);
System.out.println("main over");
}
public static void m1(int i){
System.out.println("m1 begin");
m2(i);
System.out.println("m1 over");
}
public static void m2(int i){
System.out.println("m2 begin");
m3(i);
System.out.println("m2 over");
}
public static void m3(int i){
System.out.println("m3 begin");
System.out.println(i);
System.out.println("m3 over");
}
方法重载(overload)
什么时候代码会发生方法重载?
条件1:在同一个类当中;
条件2:方法名相同;
条件3:参数列表不同(参数的个数不同、参数的类型不同、参数的顺序不同)。
只要同时满足以上3个条件,那么我们可以认定方法和方法之间发生了重载机制。
认识面向对象
面向对象
对于C语言来说,是完全面向过程的;
对于C++语言来说,是一半面向过程,一半面向对象;
对于JAVA语言来说,是完全面向对象的。
OOA、OOD、OOP
当我们采用面向对象的方式贯穿整个系统的话,涉及到三个术语:
OOA:面向对象分析;
OOD:面向对象设计;
OOP:面向对象编程。
类和对象
类—【实例化】—>对象(实例)
对象—【抽象】—>类
对象的创建和使用
对象的创建
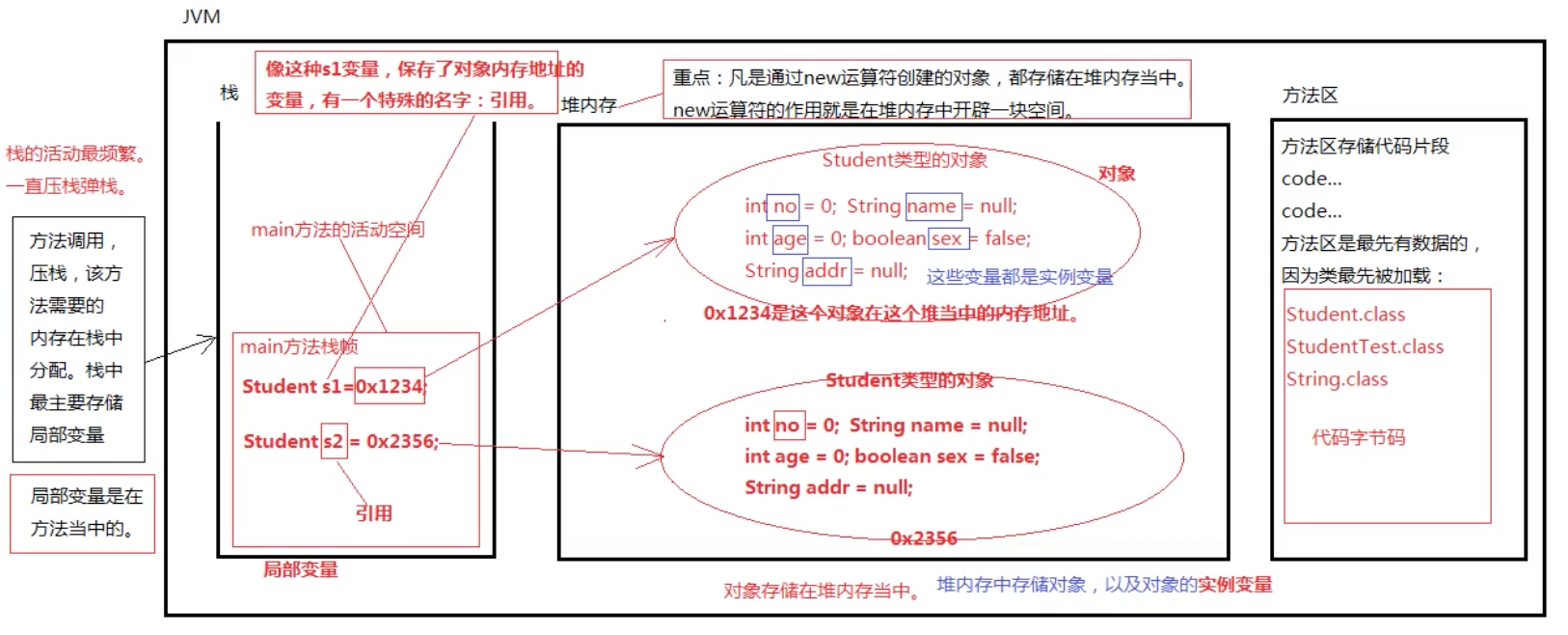
Java中所有的“类”都属于引用数据类型。
创建对象对应的JVM内存结构
public class Student{
int no;
string name;
int age;
boolean sex;
String addr;
}
public Class StudentTest{
public static void main(String[] args){
//s1这个局部变量叫做引用,指向创建的对象
Student s1=new Student();
}
}对象和引用的区别
对象是通过new出来的,在堆内存中存储;
引用是:但凡是变量,并且该变量中保存了内存地址指向了堆内存当中的对象的。
空指针异常
public class T{
A o1=new A();
public static void main(String[] args){
D d=new D();
C c=new C();
B b=new B();
A a=new A();
T t=new T();
//这里代码不写会出现NullPointerException(空指针异常)
//因为如果不写的话,t.o1的new A()之后o1是null的
c.o4=d;
b.o3=c;
a.o2=b;
t.o1=a;
System.out.println(t.o1.o2.o3.o4.i);
}
}
class A{
B o2;
}
class B{
C o3;
}
class C{
D o4;
}
class D{
int i;
}Java中的垃圾回收器GC主要针对回收的是堆内存当中的垃圾数据。当没有任何引用指向该对象的时候数据会被垃圾回收器回收。
空指针异常导致的最本质的原因是?空引用访问“实例相关的数据”,会出现空指针异常。
方法调用时参数传递
Java中关于方法调用时参数传递实际上只有一个规则:
不管你是基本数据类型,还是引用数据类型,实际上在传递的时候都是将变量中保存的那个“值”复制一份,传过去。
Person p1=0x1234;
Person p2=p1; //把p1中保存的0x1234复制一份传给p2。public class Test{
public static void main(String[] args){
Person p=new Person();
p.age=10;
add(p);
System.out.println("main--->"+p.age); //11
}
public static void add(Person p){
p.age++;
System.out.println("add--->"+p.age); //11
}
}
class Person{
int age;
}构造方法
当一个类没有提供任何构造方法,系统会默认提供一个无参数的构造方法,这个构造方法被称为缺省构造器。
当一个类中手动地提供了构造方法,那么系统将不再提供无参数构造方法。
构造器的修饰符一定是public。
构造器方法不需要指定返回值类型,也不能写void。
面向对象的三大特征
封装、继承、多态(递进)。
有了封装,才有继承;有了继承,才说多态。
封装
封装有什么用
假设封装之后,对于代码的调用人员来说,不需要关心代码的复杂实现,只需要通过一个简单的入口就可以访问了。
另外,类体中安全级别较高的数据封装起来,外部人员不能随意访问,来保证数据的安全性。
怎么进行封装
第一步:属性私有化;
第二步:对外提供简单的操作入口(一个属性对外提供set和get方法,外部程序只能通过set方法修改,只能通过get方法访问,可以在set方法中设立关卡来保证数据的安全性)。
实例方法
没有static的方法被称为实例方法。
set方法和get方法的封装
JAVA开发规范中有要求,set方法和get方法要满足以下格式。
get方法的要求:
public 返回值类型 get+属性名首字母大写(无参){
return xxx;
}set方法的要求:
public void set+属性名首字母大写(有1个参数){
xxx=参数;
}static
所有static关键字修饰的都是类相关的,类级别的。
所有static修饰的,都是采用“类名.”的方式访问。
变量的分类:
变量根据声明的位置进行划分:
在方法体当中声明的变量叫做:局部变量;
在方法体外声明的变量叫做:成员变量。
成员变量又可以分为:
实例变量;静态变量。
静态变量
该变量对于每个对象来说是相同的,即改变量与对象的不同无关,才定义为静态变量。
静态变量在类加载时初始化,不需要new对象,静态变量的空间就开出来了。
静态变量存储在方法区。
构造方法里不用写静态变量的初始化。
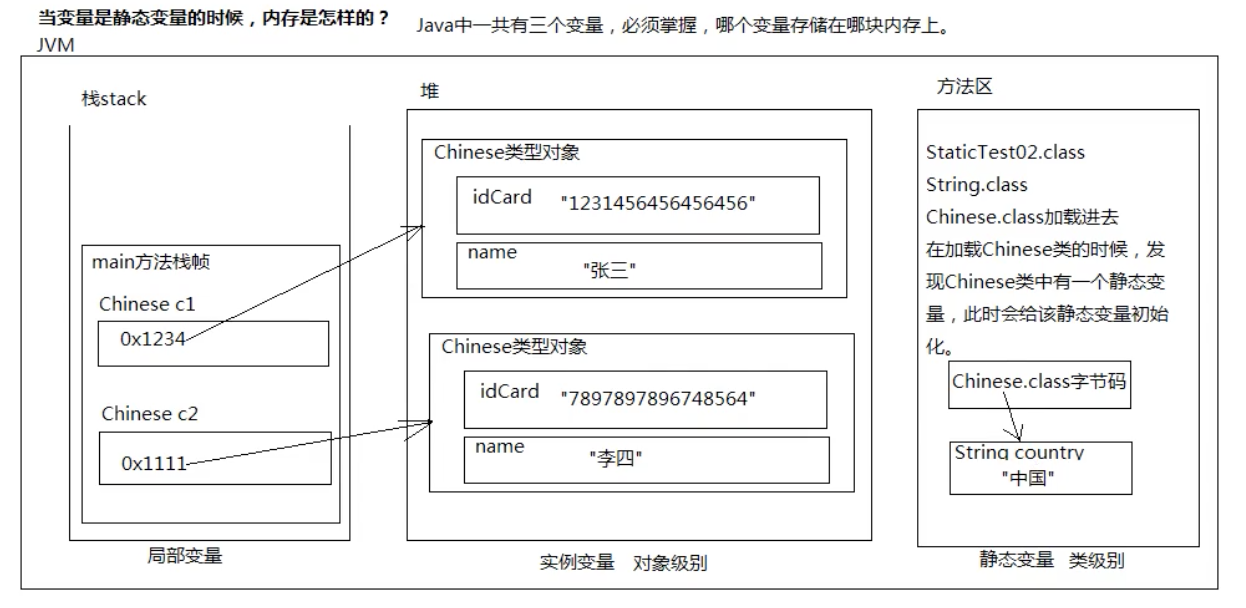
静态的(静态变量、静态方法)建议使用“类名.”来访问,但使用“引用.”也行。
空指针访问静态不会空指针。
静态方法
方法一般都是描述了一个行为,如果说该行为必须由对象去触发,那么该方法定义为实例方法。
当这个方法体中,直接访问了实例变量,那么这个方法一定是实例方法。
静态代码块
什么是静态代码块?语法是什么?
static{
java语句;
java语句;
}静态代码块在什么时候执行呢?
类加载时执行,并且只执行一次。
静态代码块在类加载时执行,并且在main方法执行之前执行。
静态代码块一般是按照自上而下的顺序执行。
public class StaticTest{
//静态代码块
static{
System.out.println("A");
}
//一个类当中可以编写多个静态代码块
static{
System.out.println("B");
}
public static void main(String[] args){
}
static{
System.out.println("C");
}
}静态代码块的作用
静态代码块这种语法机制实际上是SUN公司给java程序员的一个特殊的时刻/时机。这个时机叫做类加载时机。
具体的业务:
项目经理说了:大家注意了,所有我们编写的程序中,只要是类加载了,请记录一下类加载的日志信息(在哪年哪月哪日几时几分几秒,哪个类加载到JVM中了)。
这些记录日志的代码写到静态代码块中。
接口的静态字段
因为interface是一个纯抽象类,所以它不能定义实例字段。但是,interface是可以有静态字段的,并且静态字段必须为final类型:
public interface Person {
public static final int MALE = 1;
public static final int FEMALE = 2;
}实际上,因为interface的字段只能是public static final类型,所以我们可以把这些修饰符都去掉,上述代码可以简写为:
public interface Person {
// 编译器会自动加上public statc final:
int MALE = 1;
int FEMALE = 2;
}继承
JAVA使用extends关键字实现继承。
class Person {
private String name;
private int age;
public String getName() {...}
public void setName(String name) {...}
public int getAge() {...}
public void setAge(int age) {...}
}
class Student extends Person {
// 不要重复name和age字段/方法,
// 只需要定义新增score字段/方法:
private int score;
public int getScore() { … }
public void setScore(int score) { … }
}在OOP的术语中,我们把Person称为超类、父类、基类,把Student称为子类、扩展类。
继承树
注意到我们在定义Person的时候,没有写extends。在Java中,没有明确写extends的类,编译器会自动加上extends Object。所以,任何类,除了Object,都会继承自某个类。下图是Person、Student的继承树:
┌───────────┐
│ Object │
└───────────┘
▲
│
┌───────────┐
│ Person │
└───────────┘
▲
│
┌───────────┐
│ Student │
└───────────┘Java只允许一个class继承自一个类,因此,一个类有且仅有一个父类。只有Object特殊,它没有父类。
protected
protected关键字可以把字段和方法的访问权限控制在继承树内部,一个protected字段和方法可以被其子类,以及子类的子类所访问。
super
super关键字表示父类(超类)。子类引用父类的字段时,可以用super.fieldName。
例如:
class Student extends Person {
public String hello() {
return "Hello, " + super.name;
}
}实际上,这里使用super.name,或者this.name,或者name,效果都是一样的。编译器会自动定位到父类的name字段。
但是,在某些时候,就必须使用super。我们来看一个例子:
public class Main {
public static void main(String[] args) {
Student s = new Student("Xiao Ming", 12, 89);
}
}
class Person {
protected String name;
protected int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
class Student extends Person {
protected int score;
public Student(String name, int age, int score) {
this.score = score;
}
}运行上面的代码,会得到一个编译错误,大意是在Student的构造方法中,无法调用Person的构造方法。
这是因为在Java中,任何class的构造方法,第一行语句必须是调用父类的构造方法。如果没有明确地调用父类的构造方法,编译器会帮我们自动加一句super();。
但是,Person类并没有无参数的构造方法,因此,编译失败。
因此我们得出结论:如果父类没有默认的构造方法,子类就必须显式调用super()并给出参数以便让编译器定位到父类的一个合适的构造方法。
子类不会继承任何父类的构造方法。子类默认的构造方法是编译器自动生成的,不是继承的。
向上转型
Person p = new Student();这种把一个子类类型安全地变为父类类型的赋值,被称为向上转型(upcasting)。
向上转型实际上是把一个子类型安全地变为更加抽象的父类型:
Student s = new Student();
Person p = s; // upcasting, ok
Object o1 = p; // upcasting, ok
Object o2 = s; // upcasting, ok可以把Student类型转型为Person,或者更高层次的Object。
向下转型
Person p1 = new Student(); // upcasting, ok
Person p2 = new Person();
Student s1 = (Student) p1; // ok
Student s2 = (Student) p2; // runtime error! ClassCastException!为了避免向下转型出错,Java提供了instanceof操作符,可以先判断一个实例究竟是不是某种类型:
Person p = new Person();
System.out.println(p instanceof Person); // true
System.out.println(p instanceof Student); // false
Student s = new Student();
System.out.println(s instanceof Person); // true
System.out.println(s instanceof Student); // true
Student n = null;
System.out.println(n instanceof Student); // falseinstanceof实际上判断一个变量所指向的实例是否是指定类型,或者这个类型的子类。
从Java 14开始,判断instanceof后,可以直接转型为指定变量,避免再次强制转型。例如,对于以下代码:
Object obj = "hello";
if (obj instanceof String) {
String s = (String) obj;
System.out.println(s.toUpperCase());
}可以改写如下:
Object obj = "hello";
if (obj instanceof String s) {
System.out.println(s.toUpperCase());
}使用instanceof variable这种判断并转型为指定类型变量的语法时,必须打开编译器开关--source 14和--enable-preview。
多态(Polymorphic)
在继承关系中,子类如果定义了一个与父类方法签名完全相同的方法,被称为覆写(Override)。
Override和Overload不同的是,如果方法签名如果不同,就是Overload,Overload方法是一个新方法;如果方法签名相同,并且返回值也相同,就是Override。
方法签名由方法名称和一个参数列表(方法的参数的顺序和类型)组成。
方法名相同,方法参数相同,但方法返回值不同,也是不同的方法。在Java程序中,出现这种情况,编译器会报错。
加上@Override可以让编译器帮助检查是否进行了正确的覆写。希望进行覆写,但是不小心写错了方法签名,编译器会报错。但是@Override不是必需的。
现在,我们考虑一种情况,如果子类覆写了父类的方法:
public class Main {
public static void main(String[] args) {
Person p = new Student();
p.run(); //输出Student.run
}
}
class Person {
public void run() {
System.out.println("Person.run");
}
}
class Student extends Person {
@Override
public void run() {
System.out.println("Student.run");
}
}Java的实例方法调用是基于运行时的实际类型的动态调用,而非变量的声明类型。
多态是指,针对某个类型的方法调用,其真正执行的方法取决于运行时期实际类型的方法。
假设我们编写这样一个方法:
public void runTwice(Person p) {
p.run();
p.run();
}它传入的参数类型是Person,我们是无法知道传入的参数实际类型究竟是Person,还是Student,还是Person的其他子类,因此,也无法确定调用的是不是Person类定义的run()方法。
所以,多态的特性就是,运行期才能动态决定调用的子类方法。对某个类型调用某个方法,执行的实际方法可能是某个子类的覆写方法。这种不确定性的方法调用,究竟有什么作用?
public class Main {
public static void main(String[] args) {
// 给一个有普通收入、工资收入和享受国务院特殊津贴的小伙伴算税:
Income[] incomes = new Income[] {
new Income(3000),
new Salary(7500),
new StateCouncilSpecialAllowance(15000)
};
System.out.println(totalTax(incomes));
}
public static double totalTax(Income... incomes) {
double total = 0;
for (Income income: incomes) {
total = total + income.getTax();
}
return total;
}
}
class Income {
protected double income;
public Income(double income) {
this.income = income;
}
public double getTax() {
return income * 0.1; // 税率10%
}
}
class Salary extends Income {
public Salary(double income) {
super(income);
}
@Override
public double getTax() {
if (income <= 5000) {
return 0;
}
return (income - 5000) * 0.2;
}
}
class StateCouncilSpecialAllowance extends Income {
public StateCouncilSpecialAllowance(double income) {
super(income);
}
@Override
public double getTax() {
return 0;
}
}观察totalTax()方法:利用多态,totalTax()方法只需要和Income打交道,它完全不需要知道Salary和StateCouncilSpecialAllowance的存在,就可以正确计算出总的税。如果我们要新增一种稿费收入,只需要从Income派生,然后正确覆写getTax()方法就可以。把新的类型传入totalTax(),不需要修改任何代码。
调用super
在子类的覆写方法中,如果要调用父类的被覆写的方法,可以通过super来调用。
class Person {
protected String name;
public String hello() {
return "Hello, " + name;
}
}
Student extends Person {
@Override
public String hello() {
// 调用父类的hello()方法:
return super.hello() + "!";
}
}final
继承可以允许子类覆写父类的方法。如果一个父类不允许子类对它的某个方法进行覆写,可以把该方法标记为final。用final修饰的方法不能被Override。
如果一个类不希望任何其他类继承自它,那么可以把这个类本身标记为final。用final修饰的类不能被继承。
对于一个类的实例字段,同样可以用final修饰。用final修饰的字段在初始化后不能被修改。可以在构造方法中初始化final字段。
抽象类
抽象方法
如果父类的方法本身不需要实现任何功能,仅仅是为了定义方法签名,目的是让子类去覆写它,那么,可以把父类的方法声明为抽象方法。
class Person {
public abstract void run();
}把一个方法声明为abstract,表示它是一个抽象方法,本身没有实现任何方法语句。因为这个抽象方法本身是无法执行的,所以,Person类也无法被实例化。编译器会告诉我们,无法编译Person类,因为它包含抽象方法。
必须把Person类本身也声明为abstract,才能正确编译它:
abstract class Person {
public abstract void run();
}抽象类
无法实例化的抽象类有什么用?
因为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。因此,抽象方法实际上相当于定义了“规范”。
例如,Person类定义了抽象方法run(),那么,在实现子类Student的时候,就必须覆写run()方法:
public class Main {
public static void main(String[] args) {
Person p = new Student();
p.run();
}
}
abstract class Person {
public abstract void run();
}
class Student extends Person {
@Override
public void run() {
System.out.println("Student.run");
}
}面向抽象编程
当我们定义了抽象类Person,以及具体的Student、Teacher子类的时候,我们可以通过抽象类Person类型去引用具体的子类的实例:
Person s = new Student();
Person t = new Teacher();这种引用抽象类的好处在于,我们对其进行方法调用,并不关心Person类型变量的具体子类型:
// 不关心Person变量的具体子类型:
s.run();
t.run();这种尽量引用高层类型,避免引用实际子类型的方式,称之为面向抽象编程。
面向抽象编程的本质就是:
- 上层代码只定义规范(例如:
abstract class Person); - 不需要子类就可以实现业务逻辑(正常编译);
- 具体的业务逻辑由不同的子类实现,调用者并不关心。
接口
如果一个抽象类没有字段,所有方法全部都是抽象方法:
abstract class Person {
public abstract void run();
public abstract String getName();
}就可以把该抽象类改写为接口:interface。
interface Person {
void run();
String getName();
}所谓interface,就是比抽象类还要抽象的纯抽象接口,因为它连字段都不能有。因为接口定义的所有方法默认都是public abstract的,所以这两个修饰符不需要写出来(写不写效果都一样)。
当一个具体的class去实现一个interface时,需要使用implements关键字。举个例子:
class Student implements Person {
private String name;
public Student(String name) {
this.name = name;
}
@Override
public void run() {
System.out.println(this.name + " run");
}
@Override
public String getName() {
return this.name;
}
}我们知道,在Java中,一个类只能继承自另一个类,不能从多个类继承。但是,一个类可以实现多个interface,例如:
class Student implements Person, Hello { // 实现了两个interface
...
}术语
Java的接口特指interface的定义,表示一个接口类型和一组方法签名,而编程接口泛指接口规范,如方法签名,数据格式,网络协议等。
抽象类和接口的对比如下:
| abstract class | interface | |
|---|---|---|
| 继承 | 只能extends一个class | 可以implements多个interface |
| 字段 | 可以定义实例字段 | 不能定义实例字段 |
| 抽象方法 | 可以定义抽象方法 | 可以定义抽象方法 |
| 非抽象方法 | 可以定义非抽象方法 | 可以定义default方法 |
接口继承
一个interface可以继承自另一个interface。interface继承自interface使用extends,它相当于扩展了接口的方法。例如:
interface Hello {
void hello();
}
interface Person extends Hello {
void run();
String getName();
}继承关系
合理设计interface和abstract class的继承关系,可以充分复用代码。一般来说,公共逻辑适合放在abstract class中,具体逻辑放到各个子类,而接口层次代表抽象程度。可以参考Java的集合类定义的一组接口、抽象类以及具体子类的继承关系:
┌───────────────┐
│ Iterable │
└───────────────┘
▲ ┌───────────────────┐
│ │ Object │
┌───────────────┐ └───────────────────┘
│ Collection │ ▲
└───────────────┘ │
▲ ▲ ┌───────────────────┐
│ └──────────│AbstractCollection │
┌───────────────┐ └───────────────────┘
│ List │ ▲
└───────────────┘ │
▲ ┌───────────────────┐
└──────────│ AbstractList │
└───────────────────┘
▲ ▲
│ │
│ │
┌────────────┐ ┌────────────┐
│ ArrayList │ │ LinkedList │
└────────────┘ └────────────┘在使用的时候,实例化的对象永远只能是某个具体的子类,但总是通过接口去引用它,因为接口比抽象类更抽象:
List list = new ArrayList(); // 用List接口引用具体子类的实例
Collection coll = list; // 向上转型为Collection接口
Iterable it = coll; // 向上转型为Iterable接口default方法
在接口中,可以定义default方法。例如,把Person接口的run()方法改为default方法:
public class Main {
public static void main(String[] args) {
Person p = new Student("Xiao Ming");
p.run();
}
}
interface Person {
String getName();
default void run() {
System.out.println(getName() + " run");
}
}
class Student implements Person {
private String name;
public Student(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}实现类可以不必覆写default方法。default方法的目的是,当我们需要给接口新增一个方法时,会涉及到修改全部子类。如果新增的是default方法,那么子类就不必全部修改,只需要在需要覆写的地方去覆写新增方法。
default方法和抽象类的普通方法是有所不同的。因为interface没有字段,default方法无法访问字段,而抽象类的普通方法可以访问实例字段。
包
在Java中,我们使用package来解决名字冲突。
Java定义了一种名字空间,称之为包:package。一个类总是属于某个包,类名(比如Person)只是一个简写,真正的完整类名是包名.类名。
例如:
小明的Person类存放在包ming下面,因此,完整类名是ming.Person;
小红的Person类存放在包hong下面,因此,完整类名是hong.Person;
小军的Arrays类存放在包mr.jun下面,因此,完整类名是mr.jun.Arrays;
JDK的Arrays类存放在包java.util下面,因此,完整类名是java.util.Arrays。
在定义class的时候,我们需要在第一行声明这个class属于哪个包。
小明的Person.java文件:
package ming; // 申明包名ming
public class Person {
}在Java虚拟机执行的时候,JVM只看完整类名,因此,只要包名不同,类就不同。
包可以是多层结构,用.隔开。例如:java.util。
要特别注意:包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系。
没有定义包名的class,它使用的是默认包,非常容易引起名字冲突,因此,不推荐不写包名的做法。
我们还需要按照包结构把上面的Java文件组织起来。假设以package_sample作为根目录,src作为源码目录,那么所有文件结构就是:
package_sample
└─ src
├─ hong
│ └─ Person.java
│ ming
│ └─ Person.java
└─ mr
└─ jun
└─ Arrays.java编译后的.class文件也需要按照包结构存放。如果使用IDE,把编译后的.class文件放到bin目录下,那么,编译的文件结构就是:
package_sample
└─ bin
├─ hong
│ └─ Person.class
│ ming
│ └─ Person.class
└─ mr
└─ jun
└─ Arrays.class编译的命令相对比较复杂,我们需要在src目录下执行javac命令:
javac -d ../bin ming/Person.java hong/Person.java mr/jun/Arrays.java包作用域
位于同一个包的类,可以访问包作用域的字段和方法。不用public、protected、private修饰的字段和方法就是包作用域。例如,Person类定义在hello包下面:
package hello;
public class Person {
// 包作用域:
void hello() {
System.out.println("Hello!");
}
}Main类也定义在hello包下面:
package hello;
public class Main {
public static void main(String[] args) {
Person p = new Person();
p.hello(); // 可以调用,因为Main和Person在同一个包
}
}import
在一个class中,我们总会引用其他的class。例如,小明的ming.Person类,如果要引用小军的mr.jun.Arrays类,他有三种写法:
第一种,直接写出完整类名,例如:
// Person.java
package ming;
public class Person {
public void run() {
mr.jun.Arrays arrays = new mr.jun.Arrays();
}
}第二种写法是用import语句,导入小军的Arrays,然后写简单类名:
// Person.java
package ming;
// 导入完整类名:
import mr.jun.Arrays;
public class Person {
public void run() {
Arrays arrays = new Arrays();
}
}在写import的时候,可以使用*,表示把这个包下面的所有class都导入进来(但不包括子包的class)。
我们一般不推荐这种写法,因为在导入了多个包后,很难看出Arrays类属于哪个包。
第三种import static的语法,它可以导入一个类的静态字段和静态方法:
package main;
// 导入System类的所有静态字段和静态方法:
import static java.lang.System.*;
public class Main {
public static void main(String[] args) {
// 相当于调用System.out.println(…)
out.println("Hello, world!");
}
}import static很少使用。
Java编译器最终编译出的.class文件只使用完整类名,因此,在代码中,当编译器遇到一个class名称时:
- 如果是完整类名,就直接根据完整类名查找这个
class; - 如果是简单类名,按下面的顺序依次查找:
- 查找当前
package是否存在这个class; - 查找
import的包是否包含这个class; - 查找
java.lang包是否包含这个class。
- 查找当前
所以编写class的时候,编译器会自动帮我们做两个import动作:
- 默认自动
import当前package的其他class; - 默认自动
import java.lang.*。
注意:自动导入的是java.lang包,但类似java.lang.reflect这些包仍需要手动导入。
如果有两个class名称相同,例如,mr.jun.Arrays和java.util.Arrays,那么只能import其中一个,另一个必须写完整类名。
最佳实践
为了避免名字冲突,我们需要确定唯一的包名。推荐的做法是使用倒置的域名来确保唯一性。例如:
- org.apache
- org.apache.commons.log
- com.liaoxuefeng.sample
作用域
public
定义为public的class、interface可以被其他任何类访问:
package abc;
public class Hello {
public void hi() {
}
}上面的Hello是public,因此,可以被其他包的类访问:
package xyz;
class Main {
void foo() {
// Main可以访问Hello
Hello h = new Hello();
}
}private
推荐把private方法放到后面,因为public方法定义了类对外提供的功能,阅读代码的时候,应该先关注public方法:
package abc;
public class Hello {
public void hello() {
this.hi();
}
private void hi() {
}
}由于Java支持嵌套类,如果一个类内部还定义了嵌套类,那么,嵌套类拥有访问private的权限:
public class Main {
public static void main(String[] args) {
Inner i = new Inner();
i.hi();
}
// private方法:
private static void hello() {
System.out.println("private hello!");
}
// 静态内部类:
static class Inner {
public void hi() {
Main.hello(); //输出private hello!
}
}
}定义在一个class内部的class称为嵌套类(nested class),Java支持好几种嵌套类。
protected
protected作用于继承关系。定义为protected的字段和方法可以被子类访问,以及子类的子类:
package
包作用域是指一个类允许访问同一个package的没有public、private修饰的class,以及没有public、protected、private修饰的字段和方法。
局部变量
使用局部变量时,应该尽可能把局部变量的作用域缩小,尽可能延后声明局部变量。
final
用final修饰class可以阻止被继承:
package abc;
// 无法被继承:
public final class Hello {
private int n = 0;
protected void hi(int t) {
long i = t;
}
}用final修饰method可以阻止被子类覆写:
package abc;
public class Hello {
// 无法被覆写:
protected final void hi() {
}
}用final修饰field可以阻止被重新赋值:
package abc;
public class Hello {
private final int n = 0;
protected void hi() {
this.n = 1; // error!
}
}用final修饰局部变量可以阻止被重新赋值:
package abc;
public class Hello {
protected void hi(final int t) {
t = 1; // error!
}
}最佳实践
如果不确定是否需要public,就不声明为public,即尽可能少地暴露对外的字段和方法。
把方法定义为package权限有助于测试,因为测试类和被测试类只要位于同一个package,测试代码就可以访问被测试类的package权限方法。
一个.java文件只能包含一个public类,但可以包含多个非public类。如果有public类,文件名必须和public类的名字相同。
classpath和jar
classpath
classpath是JVM用到的一个环境变量,它用来指示JVM如何搜索class。
因为Java是编译型语言,源码文件是.java,而编译后的.class文件才是真正可以被JVM执行的字节码。因此,JVM需要知道,如果要加载一个abc.xyz.Hello的类,应该去哪搜索对应的Hello.class文件。
所以,classpath就是一组目录的集合,它设置的搜索路径与操作系统相关。例如,在Windows系统上,用;分隔,带空格的目录用""括起来,可能长这样:
C:\work\project1\bin;C:\shared;"D:\My Documents\project1\bin"在Linux系统上,用:分隔,可能长这样:
/usr/shared:/usr/local/bin:/home/liaoxuefeng/bin现在我们假设classpath是.;C:\work\project1\bin;C:\shared,当JVM在加载abc.xyz.Hello这个类时,会依次查找:
- <当前目录>\abc\xyz\Hello.class
- C:\work\project1\bin\abc\xyz\Hello.class
- C:\shared\abc\xyz\Hello.class
注意到.代表当前目录。如果JVM在某个路径下找到了对应的class文件,就不再往后继续搜索。如果所有路径下都没有找到,就报错。
classpath的设定方法有两种:
在系统环境变量中设置classpath环境变量,不推荐;
在启动JVM时设置classpath变量,推荐。
我们强烈不推荐在系统环境变量中设置classpath,那样会污染整个系统环境。在启动JVM时设置classpath才是推荐的做法。实际上就是给java命令传入-classpath或-cp参数:
java -classpath .;C:\work\project1\bin;C:\shared abc.xyz.Hello或者使用-cp的简写:
java -cp .;C:\work\project1\bin;C:\shared abc.xyz.Hello没有设置系统环境变量,也没有传入-cp参数,那么JVM默认的classpath为.,即当前目录:
java abc.xyz.Hello上述命令告诉JVM只在当前目录搜索Hello.class。
在IDE中运行Java程序,IDE自动传入的-cp参数是当前工程的bin目录和引入的jar包。
通常,我们在自己编写的class中,会引用Java核心库的class,例如,String、ArrayList等。这些class应该上哪去找?
有很多“如何设置classpath”的文章会告诉你把JVM自带的rt.jar放入classpath,但事实上,根本不需要告诉JVM如何去Java核心库查找class,JVM怎么可能笨到连自己的核心库在哪都不知道?
不要把任何Java核心库添加到classpath中!JVM根本不依赖classpath加载核心库!
更好的做法是,不要设置classpath!默认的当前目录.对于绝大多数情况都够用了。
jar包
jar包可以把package组织的目录层级,以及各个目录下的所有文件(包括.class文件和其他文件)都打成一个jar文件。
jar包实际上就是一个zip格式的压缩文件,而jar包相当于目录。如果我们要执行一个jar包的class,就可以把jar包放到classpath中:
java -cp ./hello.jar abc.xyz.Hello这样JVM会自动在hello.jar文件里去搜索某个类。
创建jar包
因为jar包就是zip包,所以,直接在资源管理器中,找到正确的目录,点击右键,在弹出的快捷菜单中选择“发送到”,“压缩(zipped)文件夹”,就制作了一个zip文件。然后,把后缀从.zip改为.jar,一个jar包就创建成功。
假设编译输出的目录结构是这样:
package_sample
└─ bin
├─ hong
│ └─ Person.class
│ ming
│ └─ Person.class
└─ mr
└─ jun
└─ Arrays.class这里需要特别注意的是,jar包里的第一层目录,不能是bin,而应该是hong、ming、mr。
如果jar包里的第一层目录是bin,JVM仍然无法从jar包中查找正确的class,原因是hong.Person必须按hong/Person.class存放,而不是bin/hong/Person.class。
jar包还可以包含一个特殊的/META-INF/MANIFEST.MF文件,MANIFEST.MF是纯文本,可以指定Main-Class和其它信息。JVM会自动读取这个MANIFEST.MF文件,如果存在Main-Class,我们就不必在命令行指定启动的类名,而是用更方便的命令:
java -jar hello.jarjar包还可以包含其它jar包,这个时候,就需要在MANIFEST.MF文件里配置classpath了。
在大型项目中,不可能手动编写MANIFEST.MF文件,再手动创建zip包。Java社区提供了大量的开源构建工具,例如Maven,可以非常方便地创建jar包。
模块
从Java 9开始,JDK又引入了模块(Module)。
我们知道,.class文件是JVM看到的最小可执行文件,而一个大型程序需要编写很多Class,并生成一堆.class文件,很不便于管理,所以,jar文件就是class文件的容器。
在Java 9之前,一个大型Java程序会生成自己的jar文件,同时引用依赖的第三方jar文件,而JVM自带的Java标准库,实际上也是以jar文件形式存放的,这个文件叫rt.jar,一共有60多M。
如果是自己开发的程序,除了一个自己的app.jar以外,还需要一堆第三方的jar包,运行一个Java程序,一般来说,命令行写这样:
java -cp app.jar:a.jar:b.jar:c.jar com.liaoxuefeng.sample.MainJVM自带的标准库rt.jar不要写到classpath中,写了反而会干扰JVM的正常运行。
从Java 9开始引入的模块,主要是为了解决“依赖”这个问题。如果a.jar必须依赖另一个b.jar才能运行,那我们应该给a.jar加点说明啥的,让程序在编译和运行的时候能自动定位到b.jar,这种自带“依赖关系”的class容器就是模块。
为了表明Java模块化的决心,从Java 9开始,原有的Java标准库已经由一个单一巨大的rt.jar分拆成了几十个模块,这些模块以.jmod扩展名标识,可以在$JAVA_HOME/jmods目录下找到它们:
- java.base.jmod
- java.compiler.jmod
- java.datatransfer.jmod
- java.desktop.jmod
- …
这些.jmod文件每一个都是一个模块,模块名就是文件名。例如:模块java.base对应的文件就是java.base.jmod。模块之间的依赖关系已经被写入到模块内的module-info.class文件了。所有的模块都直接或间接地依赖java.base模块,只有java.base模块不依赖任何模块,它可以被看作是“根模块”,好比所有的类都是从Object直接或间接继承而来。
把一堆class封装为jar仅仅是一个打包的过程,而把一堆class封装为模块则不但需要打包,还需要写入依赖关系,并且还可以包含二进制代码(通常是JNI扩展)。此外,模块支持多版本,即在同一个模块中可以为不同的JVM提供不同的版本。
编写模块
首先,创建模块和原有的创建Java项目是完全一样的,以oop-module工程为例,它的目录结构如下:
oop-module
├── bin
├── build.sh
└── src
├── com
│ └── itranswarp
│ └── sample
│ ├── Greeting.java
│ └── Main.java
└── module-info.java其中,bin目录存放编译后的class文件,src目录存放源码,按包名的目录结构存放,仅仅在src目录下多了一个module-info.java这个文件,这就是模块的描述文件。在这个模块中,它长这样:
module hello.world {
requires java.base; // 可不写,任何模块都会自动引入java.base
requires java.xml;
}其中,module是关键字,后面的hello.world是模块的名称,它的命名规范与包一致。花括号的requires xxx;表示这个模块需要引用的其他模块名。除了java.base可以被自动引入外,这里我们引入了一个java.xml的模块。
当我们使用模块声明了依赖关系后,才能使用引入的模块。例如,Main.java代码如下:
package com.itranswarp.sample;
// 必须引入java.xml模块后才能使用其中的类:
import javax.xml.XMLConstants;
public class Main {
public static void main(String[] args) {
Greeting g = new Greeting();
System.out.println(g.hello(XMLConstants.XML_NS_PREFIX));
}
}如果把requires java.xml;从module-info.java中去掉,编译将报错。可见,模块的重要作用就是声明依赖关系。
下面,我们用JDK提供的命令行工具来编译并创建模块。
首先,我们把工作目录切换到oop-module,在当前目录下编译所有的.java文件,并存放到bin目录下,命令如下:
$ javac -d bin src/module-info.java src/com/itranswarp/sample/*.java如果编译成功,现在项目结构如下:
oop-module
├── bin
│ ├── com
│ │ └── itranswarp
│ │ └── sample
│ │ ├── Greeting.class
│ │ └── Main.class
│ └── module-info.class
└── src
├── com
│ └── itranswarp
│ └── sample
│ ├── Greeting.java
│ └── Main.java
└── module-info.java下一步,我们需要把bin目录下的所有class文件先打包成jar,在打包的时候,注意传入--main-class参数,让这个jar包能自己定位main方法所在的类:
$ jar --create --file hello.jar --main-class com.itranswarp.sample.Main -C bin .现在我们就在当前目录下得到了hello.jar这个jar包,它和普通jar包并无区别,可以直接使用命令java -jar hello.jar来运行它。但是我们的目标是创建模块,所以,继续使用JDK自带的jmod命令把一个jar包转换成模块:
$ jmod create --class-path hello.jar hello.jmod于是,在当前目录下我们又得到了hello.jmod这个模块文件。
运行模块
要运行一个jar,我们使用java -jar xxx.jar命令。要运行一个模块,我们只需要指定模块名。
$ java --module-path hello.jar --module hello.world那我们辛辛苦苦创建的hello.jmod有什么用?答案是我们可以用它来打包JRE。
打包JRE
前面讲了,为了支持模块化,Java 9首先带头把自己的一个巨大无比的rt.jar拆成了几十个.jmod模块,原因就是,运行Java程序的时候,实际上我们用到的JDK模块,并没有那么多。不需要的模块,完全可以删除。
过去发布一个Java应用程序,要运行它,必须下载一个完整的JRE,再运行jar包。而完整的JRE块头很大,有100多M。怎么给JRE瘦身呢?
现在,JRE自身的标准库已经分拆成了模块,只需要带上程序用到的模块,其他的模块就可以被裁剪掉。怎么裁剪JRE呢?并不是说把系统安装的JRE给删掉部分模块,而是“复制”一份JRE,但只带上用到的模块。为此,JDK提供了jlink命令来干这件事。命令如下:
$ jlink --module-path hello.jmod --add-modules java.base,java.xml,hello.world --output jre/我们在--module-path参数指定了我们自己的模块hello.jmod,然后,在--add-modules参数中指定了我们用到的3个模块java.base、java.xml和hello.world,用,分隔。最后,在--output参数指定输出目录。
现在,在当前目录下,我们可以找到jre目录,这是一个完整的并且带有我们自己hello.jmod模块的JRE。试试直接运行这个JRE:
$ jre/bin/java --module hello.world要分发我们自己的Java应用程序,只需要把这个jre目录打个包给对方发过去,对方直接运行上述命令即可,既不用下载安装JDK,也不用知道如何配置我们自己的模块,极大地方便了分发和部署。
访问权限
前面我们讲过,Java的class访问权限分为public、protected、private和默认的包访问权限。引入模块后,这些访问权限的规则就要稍微做些调整。
确切地说,class的这些访问权限只在一个模块内有效,模块和模块之间,例如,a模块要访问b模块的某个class,必要条件是b模块明确地导出了可以访问的包。
举个例子:我们编写的模块hello.world用到了模块java.xml的一个类javax.xml.XMLConstants,我们之所以能直接使用这个类,是因为模块java.xml的module-info.java中声明了若干导出:
module java.xml {
exports java.xml;
exports javax.xml.catalog;
exports javax.xml.datatype;
...
}只有它声明的导出的包,外部代码才被允许访问。换句话说,如果外部代码想要访问我们的hello.world模块中的com.itranswarp.sample.Greeting类,我们必须将其导出:
module hello.world {
exports com.itranswarp.sample;
requires java.base;
requires java.xml;
}因此,模块进一步隔离了代码的访问权限。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!